计算机“翻译”历程
本文最后更新于:4 个月前
01 机器语言
计算机刚发明那会儿,人们就是拨弄各种开关、操作各种电缆把程序“输入”到计算机中去。
这所谓的程序,可真的是 0110000111 这样的二进制,我真是佩服这些程序的设计者和操作员们,太不可思议了。
这种原始的方式也决定了难于诞生超大型程序,因为太复杂了,远远超过人脑能思考的极限。

后来人们做了点改进,把程序打到穿孔纸带上,让机器直接读穿孔纸带,这下子就好多了,终于不用拨弄开关了。

但程序的本质还是没有变化,依然是在使用二进制来编程。
如果这个样子一直持续下去,估计这个世界上的程序员会少的可怜:编程的门槛太高了。
比如说你的脑子里得记住这样的指令:
1 | |
你还得记住每个寄存器的二进制表示:
1 | |
综合起来就像这样:
0000 1000 000000000001 它的意思是说,把编号为1的内存中的值装载到寄存器A当中
0010 1000 1001 的意思是把寄存器A和寄存器B的值加起来,放到寄存器A中。
整天生活在这样的世界里,满脑子都是0和1,人估计就抑郁了。
当时的程序员像熊猫一样稀少,不,肯定比熊猫更少,他们都要用二进制写程序。
02 汇编语言
既然二进制这么难记,人们很快就想到:能不能给这些指令起个好听的名称呢?
0000 : LOAD
0001 : STORE
0010 : ADD
寄存器也是一样的:
1000 : AX
1001 : BX
这下读来容易多了:
ADD AX BX
人们给这些帮助记忆的助记符起了个名字:汇编语言。
但是计算机是无法执行汇编语言的,因为计算机这个笨家伙只认二进制,所以还得翻译一下才行。
于是汇编器隆重登场了,他专门负责汇编语言写的程序翻译为机器语言,这个翻译的过程比较简单,几乎就是一一对应的关系。
汇编语言解放了人们的部分脑力,可以把更多的精力集中在程序逻辑上了。越来越多的人学会了使用汇编来编程,写出了很多伟大的软件。
汇编的优点是贴近机器,运行效率极高,但是缺点也是太贴近机器,直接操作内存和 CPU 寄存器,不能结构化编程,每次函数调用还得手动把栈帧给管理好,这对于一般的程序员来讲太难了!
在过去人们把穿孔纸带和汇编语言都称为低级语言,把这个时代称为机器语言编程时代。
生活在这个时代的人们是很幸福的,因为翻译工作十分简单。但是用汇编写程序的人还是太少。
03 高级语言
人类的欲望是无止境的,人们一直在探索用一种更高级的语言来写程序的可能性,这种高级语言应该面向人类编写和阅读,而不是面向机器去执行。
人类想要的高级语言是这样的:
声明各种类型的变量来表示数据,而不是用寄存器。例如:
int value = 100
能使用复杂的表达式来告诉电脑自己的意图:
salary = 1000 + salary * 12
可以用各种控制语句来控制流程:
if .. else , while(....) ....
还可以定义函数来封装、复用一段业务逻辑:
int get_primes(int max) {.....}
但是高级语言和低级语言之间存在着巨大的鸿沟,怎么把高级语言翻译成可以执行的机器语言是个非常难的问题!
人类在黑暗中摸索了很久才迎来一丝光明,1957年,第一个高级语言的编译器才在 IBM704 的机器上运行成功。更重要的是乔姆斯基对自然语言结构的研究,把语言文法做了分类,有了 0 型文法,1 型文法,2 型文法,3 型文法,这一下子给人们的翻译工作奠定了理论基础。
由于翻译的复杂性,除了汇编器之外,很多新成员加入进来,大家分工合作,把高级语言翻译成低级语言。
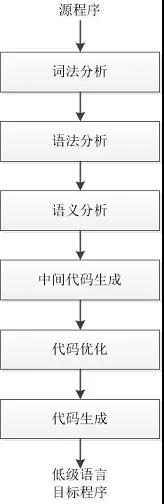
第一步 词法分析
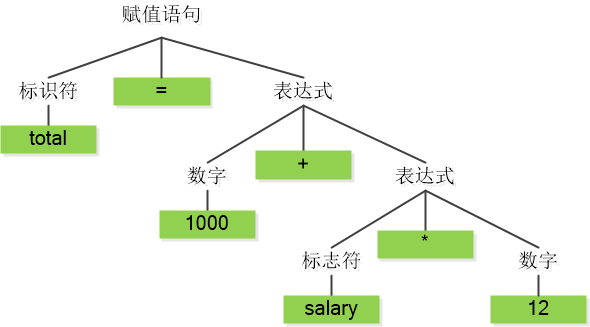
比如高级语言的源程序是这样:
total = 1000 + salary * 12
我们把它看成一个个的片段,每个片段叫做 Token。
- 标识符 total
- 赋值符号 =
- 数字 1000
- 加号 +
- 标识符 salary
- 乘号 *
- 数字12
程序中的空格被无情的删除了,但是底层编译的人们还会建立一个符号表让后面的人去使用:
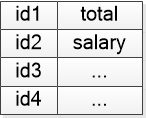
第二步 二叉树就会接管,它非常厉害,会做语法分析,用一个上下文无关的语法理论,把之前生成的 Token 按照语法规则组建成一棵树
第三步 做语法分析,要看看这些标志符的类型,作用域是不是正确,运算是否合法,取值范围有没有问题等等。
第四步 最重要,把中间代码生成,代码优化,以及最后的代码生成。
比如第四步根据语法树生成的中间代码如下:
temp1 = id2 * 12 //把id2乘12的值赋值给temp1
temp2 = 1000 + temp1 //把1000+temp1的值赋值给temp2
id1 = temp2 //把temp2的值赋值给id1
注意:id2 就是 salary, id1 就是 total
然后再优化一下:
temp1 = id2 * 12 //把id2乘12的值赋值给temp1
id1 = 1000 + temp1 //把1000+temp1的值赋值给id1
然后翻译成汇编:
MOV id2 AX
MUL 12 AX
ADD 1000 AX
MOV AX id1
这已经非常接近运行了!
但是,这id1(total),id2 (salary) 只是两个符号,计算机根本不知道是什么东西,计算机只关心内存和寄存器,所以还得给这两个家伙分配空间,得到他们的地址。
如果这两个变量是在别的文件中定义的,还需要做一件特别的事情:链接!
通过链接的方式,把变量的真正地址获取到,然后修改上面的id1, id2, 这样才能形成一个可以执行的程序。
在翻译的过程中,如果有任何步骤出了错误,控制台就会通知程序员,告诉他哪个地方写错了,改正后重新再来。
这非常重要,没有这项翻译工作,人类就无法使用高级语言来编程,像C, C++, Pascal, C#, Java 这样影响力巨大的语言就不会出现。
底层汇编器、链接器、编译器、解释器和操作系统、数据库、网络协议栈等软件一起,成为了计算机世界底层的基础软件。
现在所谓的高级语言一点也不高级,只有经过训练的专业人士才能使用,希望在未来会出现完全用自然语言来写程序。这样世界会变得无比的和谐。 👀